

|
Author: David Masri Founder & CEO |
PK Chunking is a feature that was added to the bulk API back in 2015, that when used, is supposed to improve the performance of large data downloads from Salesforce. Most native objects and all custom objects are supported (official documentation with details here).
Basically when sending a Bulk API request, as part of the header we tell Salesforce to use PK Chunking and the Chunck Size. Then when processing the request, Salesforce will get the Min & Max Ids (or Primary Keys - PKs) of the object, then create a set of SOQL statements, where each statement has a where clause specifying a "Chunk" of Primary Keys (PKs).
For example, suppose we send the query "Select Name from Account", and we specify to use PKChunking and set a ChuckSize of 200k. Lets say there are 1MM records in the object and the Min ID is 10005 and the Max ID is 2010005 (I know Salesforce doesn't use numeric Ids, but I am pretending it does for the sake of making this example easy to understand). Salesforce will break the SOQL into chunks, like so:
SELECT Name FROM Account WHERE Id >= 10005 AND Id < 1010005 SELECT Name FROM Account WHERE Id >= 1010005 AND Id < 1210005 SELECT Name FROM Account WHERE Id >= 1210005 AND Id < 1410005 SELECT Name FROM Account WHERE Id >= 1410005 AND Id < 1610005 SELECT Name FROM Account WHERE Id >= 1610005 AND Id < 1810005 SELECT Name FROM Account WHERE Id >= 1810005 AND Id < 2010005
Salesforce then combines the results, and returns the data as a single data set. Now, we can specify our own where clause and still use PK Chunking, but this can backfire if our result data set is small (or is already very selective - see the next section).
For example, suppose we send the following SOQL:
Select Name from Account where ID=1418955 If we specified PK Chunking Salesforce will still break up the SOQL into chunks, like so:
SELECT Name FROM Account WHERE Id >= 10005 AND Id < 1010005 SELECT Name FROM Account WHERE Id >= 1010005 AND Id < 1210005 and ID=1418955 SELECT Name FROM Account WHERE Id >= 1210005 AND Id < 1410005 and ID=1418955 SELECT Name FROM Account WHERE Id >= 1410005 AND Id < 1610005 and ID=1418955 SELECT Name FROM Account WHERE Id >= 1610005 AND Id < 1810005 and ID=1418955 SELECT Name FROM Account WHERE Id >= 1810005 AND Id < 2010005 and ID=1418955
Now, clearly this bad. But this brings up the next question:
It seems nuts? If we am returning all the data in an object, why would breaking it up into smaller chunks be faster? So I tested it. and low and behold it is faster, much faster, sometime 85% faster (my tests where unscientific, so I don't want to share the exact results). Not only that, Salesforce says:
But my test only has 3MM records and I still got much better performance! Why?
According to Salesforce it's because:
But again you might ask "But I'm returning all the data", why should selectivity matter? It needs to read all rows!". The answer to this is because Salesforce is a Multi-Tenant system, so there is always a "where" clause on your SOQL to filter data only for your Org and security permissions. Adding the Ids makes it more selective.
Oh, remind me again, What is Selectivity?
From the Oracle Docs:
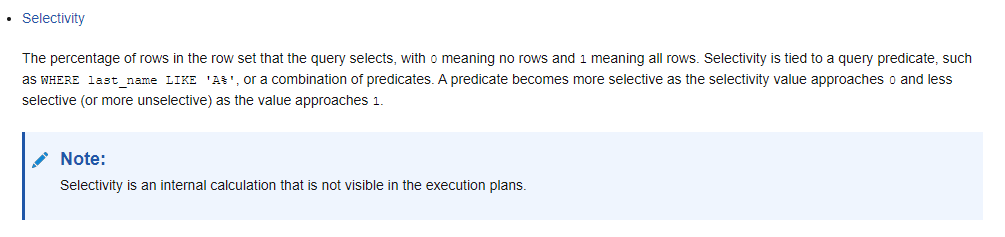
Going into more detail then this would be way too technical for this article but if you are interested, you can check out this video on SOQL Tuning and Selectivity Thresholds:
This article is adapted from my book: Developing Data Migrations and Integrations with Salesforce.
Have a question you would like to as see a part of my FAQ blog series? Email it to me! Dave@Gluon.Digital